
I am a Research Scientist at Meta, working on AI/ML systems to enhance how people explore and engage with visual content. I earned my Ph.D. in Computer Science from Columbia University under Brian A. Smith in the Computer-Enabled Abilities Lab, focusing on AI-driven accessibility for blind and low-vision users. My work bridges academia and industry, designing systems that empower exploratory, user-driven interaction with visual information across diverse contexts. I also interned at Apple's Human-Centered Machine Intelligence team, where I worked on AI-driven accessibility solutions.
AI-Driven Interactive Systems for Agency in Access to Visual Experiences
I design, build, and evaluate AI-driven systems to augment visual experiences. My work focuses on fostering exploration and agency, spanning accessibility for blind and low-vision (BLV) users and innovative approaches to video exploration.
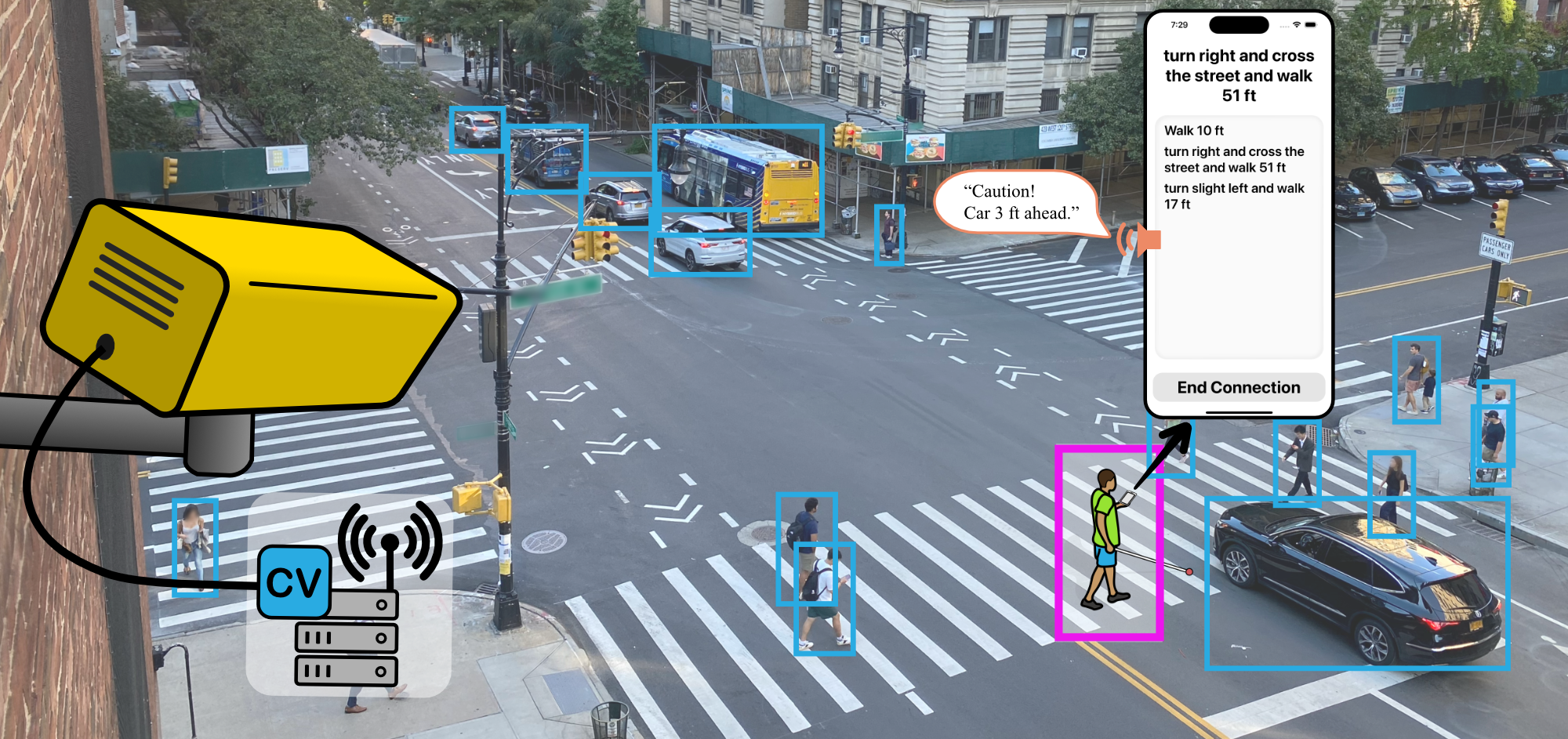
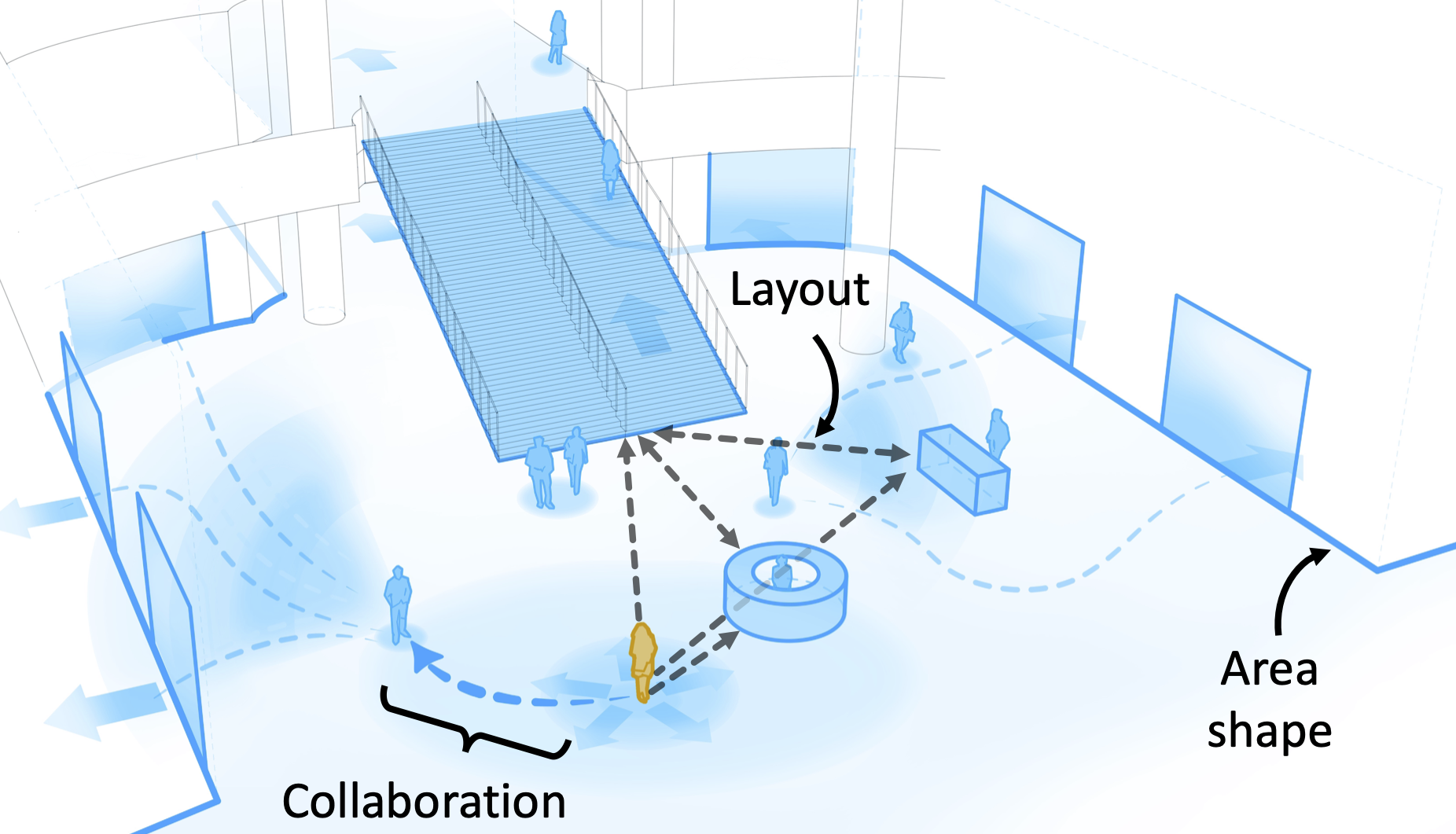
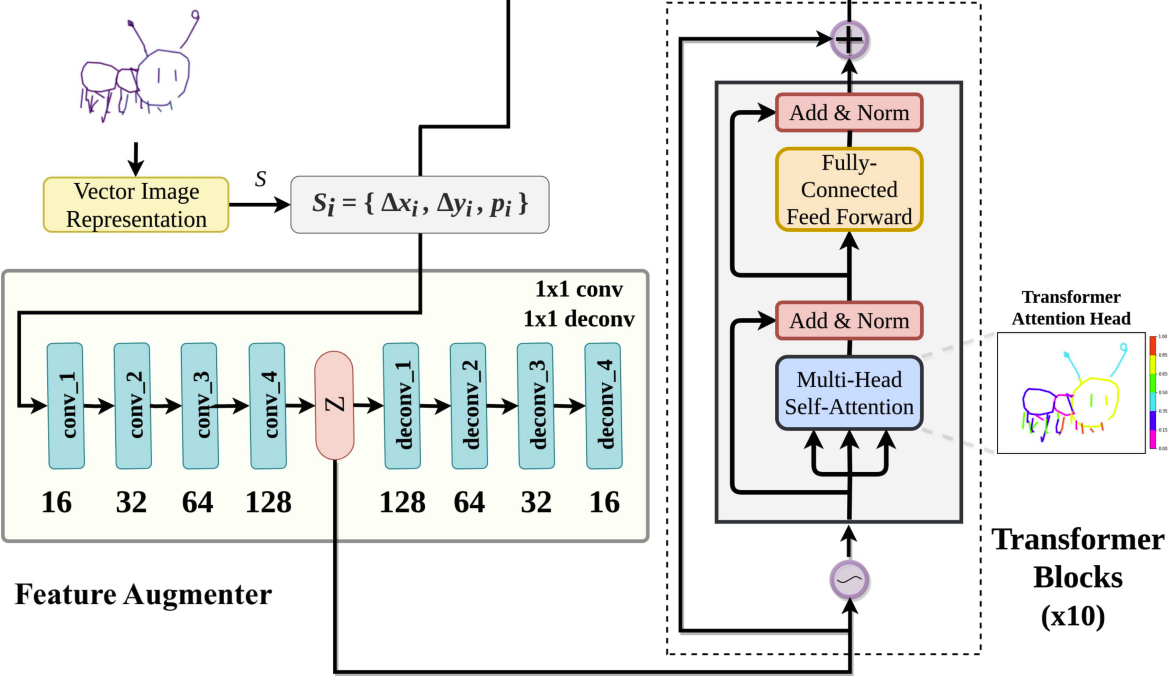
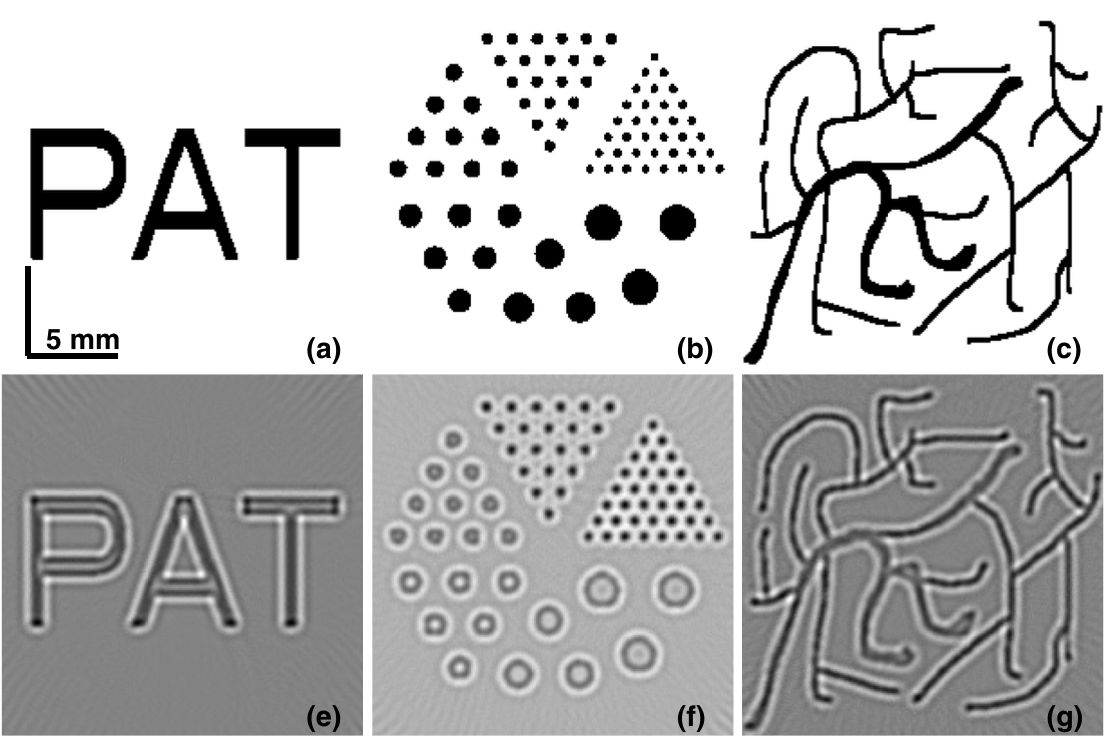
My systems allow BLV users to independently visualize action in sports broadcasts via 3D spatial audio (CHI 2023, UIST 2023), embed AI within streets to help BLV users navigate safely outdoors (ASSETS 2023, UIST 2024), and leverage multimodal AI to enable exploration of street view imagery with rich contextual understanding (CHI 2026). To guide these designs, I also conduct qualitative studies to understand user needs. My work introduced the concept of "exploration assistance systems," characterizing systems that scaffold the process of exploration (CSCW 2023), earning an Impact Recognition Award 🏆.
At Meta, I leverage AI/ML techniques to transform how users interact with videos. My work focuses on enabling user-driven exploration of long-form videos, allowing users to navigate chapters, discover key moments, and engage with the most relevant content seamlessly.
News
-
[Jan '26] 🎉 SceneScout accepted at CHI 2026; work done during my Apple internship.
-
[Oct '25] 💼 Started new role as a Research Scientist at Meta.
-
[May '25] 🏆 Received the PhD Service Award for outstanding contributions to the CS department.
-
[Apr '25] 📄 SceneScout is now on arXiv (Apple internship project).
-
[Oct '24] ✈️ Attending UIST 2024 in Pittsburgh to present this paper.
-
[May '24] 🍎 Starting internship at Apple in Seattle!
-
[May '24] ✈️ Attending CHI 2024 in Hawaii 🏝️, and serving as a student volunteer.
-
[Apr '24] 🌟 Completed my PhD Thesis Proposal.
-
[Apr '24] 🙋♂️ Excited to serve as Publicity Co-chair for UIST 2024.
-
[Nov '23] 🎙️ Gave a talk at the Vision Zero Research Symposium to NYC Govt. officials on StreetNav.
-
[Oct '23] ✈️ Attending UIST 2023 in San Francisco to present this paper (Talk).
-
[Oct '23] ✈️ Attending ASSETS 2023 in New York to present this poster.
-
[Oct '23] ✈️ Attending CSCW 2023 in Minneapolis to present this paper.
Read More
-
[Sep '23] 🏆 Paper wins Impact Recognition Award at CSCW 2023.
-
[Sep '23] 📄 StreetNav is now on arXiv. This full paper extends our ASSETS 2023 poster.
-
[Aug '23] 🎉 Poster accepted at ASSETS 2023.
-
[Jun '23] 🙋♂️ Excited to serve as student volunteer at ASSETS 2023.
-
[Jun '23] 🧑💻 Attended annual meeting for the NSF Center for Smart Streetscapes (CS3).
-
[Apr '23] 🎙️ CSCW'23 paper received press coverage in interview with the CS department.
-
[Mar '23] 🏆 Awarded SIGCHI's Gary Marsden Travel Award to attend CHI 2023.
-
[Feb '23] 🎉 Late-Breaking Work accepted at CHI 2023!
-
[Dec '22] 🌟 Passed my candidacy exam: Watching Videos Without Vision (slides).
-
[Nov '22] 🎉 Paper accepted at CSCW 2023!
Read Less
Selected Publications
For an updated list of articles, please visit my Google Scholar profile.





Contact
If you’re interested in my work and wish to discuss anything, feel free to email me (gaurav [at] cs [dot] columbia [dot] edu)!